- 워드 임베딩은 단어를 컴퓨터가 이해하고, 효율적으로 처리할 수 있도록 단어를 벡터화하는 기술이다.
- 워드 임베딩은 단어의 의미를 잘 표현해야만 하며, 현재까지도 많은 표현 방법이 연구되고 있다.
- 워드 임베딩을 거쳐 잘 표현된 단어 벡터들은 계산이 가능하며, 모델에 넣는 것이 가능해진다.
1. 인코딩(Encoding)
- 기계는 자연어를 이해할 수 없다. 그렇기에, 데이터를 기계가 잘 이해할 수 있도록 숫자 등으로 변환해주는 작업이 필요하다. 이러한 작업을 인코딩이라고 한다.
- 텍스트 처리에서는 주로 정수 인코딩, 원-핫 인코딩을 사용한다.
정수 인코딩
- 각 단어와 정수 인덱스를 연결하고 토큰을 변환해주는 정수 인코딩
text='평생 살 것처럼 꿈을 꾸어라. 그리고 내일 죽을 것처럼 오늘을 살아라.'
tokens=[x for x in text.split(' ')]
unique=set(tokens)
unique=list(unique)
token2idx={}
for i in range(len(unique)):
token2idx[unique[i]]=i
encode=[token2idx[x] for x in tokens]
encode
-------------------------------------
[1, 2, 6, 3, 4, 9, 0, 8, 6, 5, 7]
Keras를 이용한 정수 인코딩
- 정수 인코딩은 단어에 정수로 label을 부여하는 것이다.
- 자동으로 단어 비니도가 높은 단어의 인덱스는 낮게끔 설정한다.
from tensorflow.keras.preprocessing.text import Tokenizer
text='평생 살 것처럼 꿈을 꾸어라. 그리고 내일 죽을 것처럼 오늘을 살아라.'
t=Tokenizer()
t.fit_on_texts([text])
print(t.word_index)
encoded=t.texts_to_sequences([text])[0]
print(encoded)
--------------------------------------------------------------------
{'것처럼': 1, '평생': 2, '살': 3, '꿈을': 4, '꾸어라': 5, '그리고': 6, '내일': 7, '죽을': 8, '오늘을': 9, '살아라': 10}
[2, 3, 1, 4, 5, 6, 7, 8, 1, 9, 10]원-핫 인코딩(One-Hot Encoding)
- 조건문과 반복문을 이용한 원-핫 인코딩
- 원-핫 인코딩은 정수 인코딩한 결과를 벡터로 변환한 인코딩이다.
- 원-핫 인코딩은 전체 단어 개수 만큼의 길이를 가진 배열에 해당 정수를 가진 위치는 1, 나머지는 0을 가진 벡터로 변환한다.
import numpy as np
one_hot=[]
for i in range(len(encoded)):
temp=[]
for j in range(max(encoded)):
if j==(encoded[i]-1):
temp.append(1)
else:
temp.append(0)
one_hot.append(temp)
np.array(one_hot)
-------------------------------
array([[0, 1, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 1, 0, 0],
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 1]])
Keras를 이용한 원-핫 인코딩
from tensorflow.keras.utils import to_categorical
one_hot=to_categorical(encoded)
one_hot
-------------------------------------------------
array([[0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0.],
[0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1.]], dtype=float32)2. IMDB 데이터
- 양극단의 리뷰 5만개로 이뤄진 인터넷 영화 데이터베이스이다.
- 훈련 데이터: 25,000개
- 테스트 데이터: 25,000개
Module Import
from tensorflow.keras.datasets import imdb
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding,Dense,Flatten
데이터 로드
num_words=1000
(x_train,y_train),(x_test,y_test)=imdb.load_data(num_words=num_words)
print(x_train.shape)
print(y_train.shape)
print(x_test.shape)
print(y_test.shape)
---------------------------------------------------------------------
(25000,)
(25000,)
(25000,)
(25000,)
데이터 확인
- 긍정: 1
- 부정: 0
print(x_train[0])
print(y_train[0])
-----------------
[1, 14, 22, 16, 43, 530, 973, 2, 2, 65, 458, 2, 66, 2, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 2, 2, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2, 19, 14, 22, 4, 2, 2, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 2, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2, 2, 16, 480, 66, 2, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 2, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 2, 15, 256, 4, 2, 7, 2, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 2, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2, 56, 26, 141, 6, 194, 2, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 2, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 2, 88, 12, 16, 283, 5, 16, 2, 113, 103, 32, 15, 16, 2, 19, 178, 32]
1
데이터 전처리
- 모든 데이터를 같은 길이로 맞춘다.
- 문장을 같은 길이로 맞추어야 Embedding layer를 사용할 수 있다.
from tensorflow.keras.preprocessing.sequence import pad_sequences
max_len=100
pad_x_train=pad_sequences(x_train,maxlen=max_len,padding='pre')
pad_x_test=pad_sequences(x_test,maxlen=max_len,padding='pre')
print(len(x_train[1]))
print(len(pad_x_train[1]))
------------------------------------------------------------------
189
100
모델 구성
model=Sequential()
model.add(Embedding(input_dim=num_words,output_dim=32,
input_length=max_len))
model.add(Flatten())
model.add(Dense(1,activation='sigmoid'))
model.summary()
------------------------------------------------------
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 100, 32) 32000
flatten (Flatten) (None, 3200) 0
dense (Dense) (None, 1) 3201
=================================================================
Total params: 35,201
Trainable params: 35,201
Non-trainable params: 0
_________________________________________________________________
모델 컴파일 및 학습
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
history=model.fit(pad_x_train,y_train,
epochs=10,
batch_size=32,
validation_split=0.2 )
시각화
import matplotlib.pyplot as plt
plt.style.use('seaborn-white')
hist_dic=history.history
hist_dic.keys()
-------------------------------
dict_keys(['loss', 'acc', 'val_loss', 'val_acc'])plt.plot(hist_dic['loss'],'b-',label='Train Loss')
plt.plot(hist_dic['val_loss'],'r:',label='Validation Loss')
plt.legend()
plt.grid()
plt.figure()
plt.plot(hist_dic['acc'],'b-',label='Train Accuracy')
plt.plot(hist_dic['val_acc'],'r:',label='Validation Accuracy')
plt.legend()
plt.grid()
plt.show()| Accuracy | Loss |
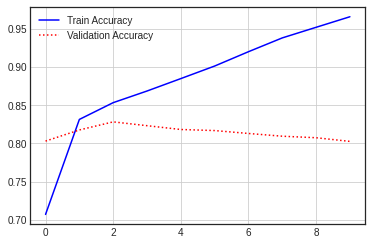 |
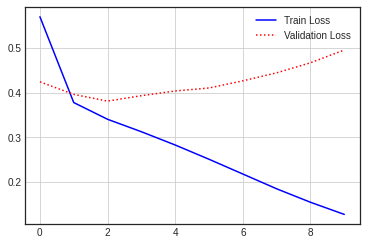 |
모델 평가
model.evaluate(pad_x_test,y_test)
---------------------------------
[0.4802447557449341, 0.8067200183868408]
단어의 수를 늘린 다음 재학습
| Accuracy | Loss |
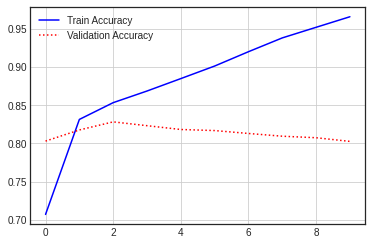 |
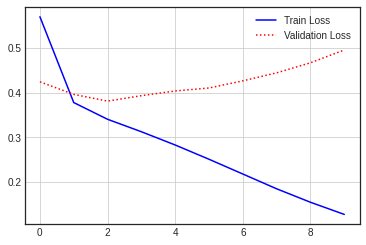 |
model.evaluate(pad_x_test_2,y_test)
-----------------------------------
[0.17259690165519714, 0.9444400072097778]
- 위의 결과도 나쁘지 않으나 과적합이 되는 이유
- 단어 간 관계나 문장 구조 등 의미적 연결을 고려하지 않았다.
- 시퀀스 전체를 고려한 특성을 학습하는 것은 Embedding layer 위에 RNN layer나 1D Conv layer를 추가하는 것이 좋다.
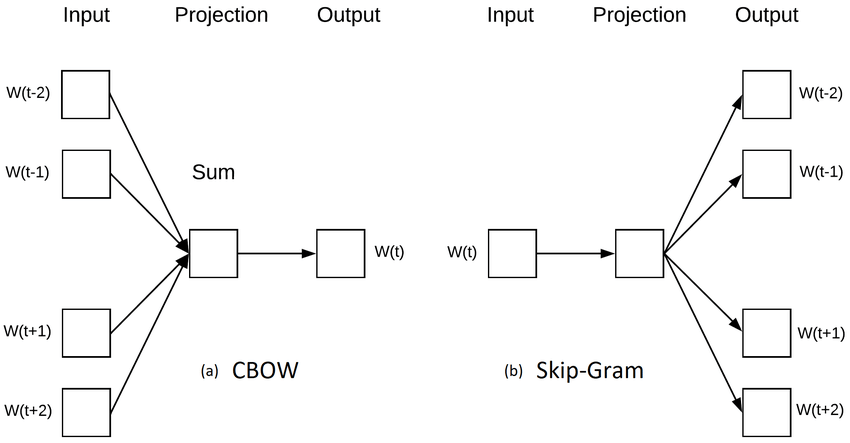
3. Word2Vec
- 2013년, Mikolov와 동료들이 제안한 모형이다.
- 분류 등과 같이 별도의 label없이 텍스트 자체만 있어도 학습이 가능하다.
- Word2Vec의 방식
- 주변 단어의 관계를 이용
- CBOW(Continuous Bag-Of-Words)
- 주변 단어의 임베딩을 더해서 대상 단어를 구축한다.
- Skip-Gram
- 대상 단어의 임베딩으로 주변 단어를 예측한다.
- 일반적으로 CBOW보다 성능이 좋은 편이다.
- 한번에 여러 단어를 예측해야하기 때문에 비효율적이다.
4. T-SNE
- T-SNE(T-Stochastic Neighbor Embedding)는 고차원의 벡터들의 구조를 보존하며 저차원으로 사상하는 차원 축소 알고리즘이다.
- 단어 임베딩에서도 생성된 고차원 벡터들을 시각화하기 위해 T-SNE 알고리즘을 많이 이용한다.
- T-SNE는 가장 먼저 원 공간의 데이터 유사도 $p_{ij}$와 임베딩 공간의 데이터 유사도 $q_{ij}$를 정의한다.
- $x_i$에서 $x_j$ 간의 유사도 $p_{j|i}$는 다음과 같이 정의한다.
$$ p_{j|i} = \frac{exp({-\mid x_i - x_j \mid }^2 / 2\sigma^2_i)}{\sum\limits_{k \neq i} exp({-\mid x_i -x_k \mid}^2 / 2\sigma^2_i)} $$
- $p_{j|i}$는 $x_i$와 $x_j$ 간의 거리에서 가중치 $\sigma^2_i$로 나눈 후, 이를 negative exponential을 취해 모든 점 간의 거리의 합과 나누어준 값으로 두 점 간의 거리가 가까울 수록 큰 값을 가진다.
- 또한 임베딩 공간에서의 $y_i$에서 $y_j$ 간의 유사도 $q_{j|i}$는 다음과 같이 정희한다.
$$ q_{j|i} = \frac{{(1+{\mid y_i - y_j \mid}^2)}^{-1}}{\sum\limits_{k \neq l} {(1+{\mid y_i - y_j \mid}^2)}^{-1} } $$
- $q_{j|i}$는 $x_i$와 $x_j$ 간의 거리에서 1을 더해준 후 역수를 취한 값과 전체 합산 값과 나누어 유사도를 정의한다.
- T-SNE의 학습은 $p_{j|i}$와 비슷해지도록 $q_{j|i}$의 위치를 조정하는 것이라고 할 수 있다.
5. Gensim을 이용한 Word2Vec
데이터 준비
from sklearn.datasets import fetch_20newsgroups
dataset=fetch_20newsgroups(shuffle=True,random_state=1,
remove=('headers','footers','quotes'))
documents=dataset.data
print(len(documents))
-----------------------------------------------------------------
11314
import re
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
nltk.download('popular')
def clean_text(d):
pattern=r'[^a-zA-Z\s]'
text=re.sub(pattern,'',d)
return d
def clean_stopword(d):
stop_words=stopwords.words('english')
return ' '.join([w.lower() for w in d.split() if w not in stop_words and len(w)>3])
def tokenize(d):
return word_tokenize(d)import pandas as pd
news_df=pd.DataFrame({'article':documents})
len(news_df)
-------------------------------------------
11314news_df.replace('',float('NaN'),inplace=True)
news_df.dropna(inplace=True)
print(len(news_df))
---------------------------------------------
11096news_df['article']=news_df['article'].apply(clean_text)
news_df['article']
-------------------------------------------------------
0 Well i'm not sure about the story nad it did s...
1 \n\n\n\n\n\n\nYeah, do you expect people to re...
2 Although I realize that principle is not one o...
3 Notwithstanding all the legitimate fuss about ...
4 Well, I will have to change the scoring on my ...
...
11309 Danny Rubenstein, an Israeli journalist, will ...
11310 \n
11311 \nI agree. Home runs off Clemens are always m...
11312 I used HP DeskJet with Orange Micros Grappler ...
11313 ^^^^^^\n...
Name: article, Length: 11096, dtype: objectnews_df['article']=news_df['article'].apply(clean_stopword)
news_df['article']
-----------------------------------------------------------
0 well sure story seem biased. what disagree sta...
1 yeah, expect people read faq, etc. actually ac...
2 although realize principle strongest points, w...
3 notwithstanding legitimate fuss proposal, much...
4 well, change scoring playoff pool. unfortunate...
...
11309 danny rubenstein, israeli journalist, speaking...
11310
11311 agree. home runs clemens always memorable. kin...
11312 used deskjet orange micros grappler system6.0....
11313 ^^^^^^ argument murphy. scared hell came last ...
Name: article, Length: 11096, dtype: object
from nltk.tokenize.treebank import TreebankWordDetokenizer
import numpy as np
tokenized_news=news_df['article'].apply(tokenize)
tokenized_news=tokenized_news.to_list()
drop_news=[index for index,sentence in enumerate(tokenized_news) if len(sentence)<=1]
news_texts=np.delete(tokenized_news,drop_news,axis=0)
print(len(news_texts))
-------------------------------------------------------------------------------------
10991CBOW
from gensim.models import Word2Vec
model=Word2Vec(sentences=news_texts,window=4,
size=100,min_count=5,workers=4,sg=0)
model.wv.similarity('man','woman')
---------------------------------------------------
0.8443312
model.most_similar(positive=['soldiers'])
-----------------------------------------
model.most_similar(positive=['soldiers'])
[('villages', 0.972125768661499),
('killed', 0.971953272819519),
('turks', 0.9572437405586243),
('genocide', 0.952102541923523),
('civilians', 0.9454869627952576),
('murdered', 0.9449344873428345),
('troops', 0.9433315396308899),
('land', 0.9423595666885376),
('wounded', 0.9399513006210327),
('lived', 0.9399234056472778)]model.wv.most_similar(positive=['man','soldiers'],negative=['woman'])
---------------------------------------------------------------------
[('assad', 0.8943959474563599),
('prophet', 0.8927676677703857),
('son', 0.8921844363212585),
('men', 0.8914796113967896),
('jews', 0.8849947452545166),
('followers', 0.8843129277229309),
('homosexual', 0.882552444934845),
('writings', 0.8810793161392212),
('war', 0.8796819448471069),
('turkey', 0.8727943897247314)]Skip-Gram
from gensim.models import Word2Vec
model=Word2Vec(sentences=news_texts,window=4,
size=100,min_count=5,workers=4,sg=1)
model.wv.similarity('man','woman')
---------------------------------------------------
0.8394786
model.most_similar(positive=['soldiers'])
-----------------------------------------
model.most_similar(positive=['soldiers'])
[('villages', 0.9280030727386475),
('azerbaijanis', 0.9278096556663513),
('wounded', 0.9268628358840942),
('refugees', 0.9141096472740173),
('azeri', 0.9075378179550171),
('troops', 0.8982663154602051),
('kurds', 0.896904706954956),
('turks', 0.8958738446235657),
('survivors', 0.894892156124115),
('village', 0.8947358131408691)]model.wv.most_similar(positive=['man','soldiers'],negative=['woman'])
---------------------------------------------------------------------
[('civilians', 0.8306970596313477),
('palestinians', 0.8227686882019043),
('muslims', 0.8206495642662048),
('azeris', 0.8105562925338745),
('germans', 0.8050326704978943),
('fighters', 0.8012163043022156),
('israelis', 0.7999339699745178),
('jews', 0.7961974740028381),
('babies', 0.7925974726676941),
('arabs', 0.7877171039581299)]
'Study' 카테고리의 다른 글
| [NLP] 9. Sentiment Analysis (4) | 2024.08.25 |
|---|---|
| [NLP] 8. 스팸 메일 분류 (0) | 2024.08.25 |
| [NLP] 6. Topic Modeling (0) | 2024.08.21 |
| [NLP] 5. Semantic Network Analysis (0) | 2024.08.20 |
| [NLP] 4. Document Classification (0) | 2024.08.20 |



